ACM MM 2022
Self-Aligned Concave Curve: Illumination
Enhancement for Unsupervised Adaptation
Abstract
Low light conditions not only degrade human visual experience, but also reduce the performance of downstream machine analytics. Although many works have been designed for low-light enhancement or domain adaptive machine analytics, the former considers less on high-level vision, while the latter neglects the potential of image-level signal adjustment. How to restore underexposed images/videos from the perspective of machine vision has long been overlooked. In this paper, we are the first to propose a learnable illumination enhancement model for high-level vision. Inspired by real camera response functions, we assume that the illumination enhancement function should be a concave curve, and propose to satisfy this concavity through discrete integral. With the intention of adapting illumination from the perspective of machine vision without task-specific annotated data, we design an asymmetric cross-domain self-supervised training strategy. Our model architecture and training designs mutually benefit each other, forming a powerful unsupervised normal-to-low light adaptation framework. Comprehensive experiments demonstrate that our method surpasses existing low-light enhancement and adaptation methods and shows superior generalization on various low-light vision tasks, including classification, detection, action recognition, and optical flow estimation. All of our data, code, and results will be available online upon publication of the paper.
Video Introduction (YouTube)
Framework
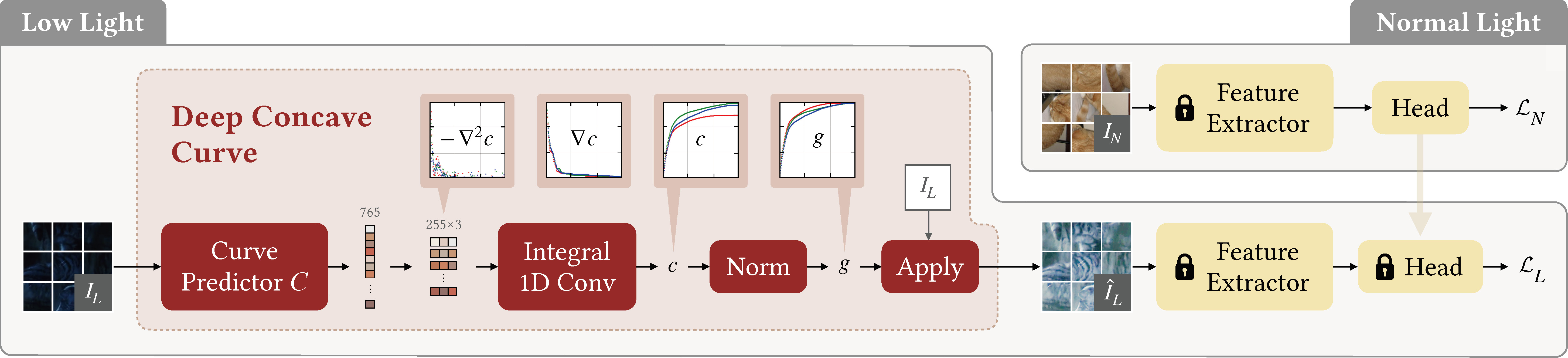
The framework of our model. Our model first predicts a non-negative minus second derivative, and then integrates and normalizes it into a concave curve g, which controls the illumination of the enhanced result. The model is trained in an asymmetric self-supervised way. Based on a pretrained and fixed-weight feature extractor, we first train a pretext head on normal light images, and then train our model with the fixed-weight pretext head on low-light images.
Selected Experimental Results

Subjective comparison results for dark face detection. The color of the bounding boxes represents the confidence of recognition, with yellow indicating higher confidence.

Optical flow estimation results of the same scene under different illumination levels.

Subjective results for video action recognition.
Citation
@InProceedings{SACC_2022_ACMMM,
author = {Wang, Wenjing and Xu, Zhengbo and Huang, Haofeng and Liu, Jiaying},
title = {Self-Aligned Concave Curve: Illumination Enhancement for Unsupervised Adaptation},
booktitle = {Proceedings of the ACM International Conference on Multimedia},
month = {October},
year = {2022}
}