
Figure 1. Representative text effects in TE141K. Text styles are grouped into three subsets based on the glyph type, including TE141K-E (English alphabet subset, 67 styles), TE141K-C (Chinese character subset, 65 styles), and TE141K-S (Symbol and other language subset, 20 styles).
Abstract
Text effects are combinations of visual elements such as outlines, colors and textures of text, which can dramatically improve its artistry. Although text effects are extensively utilized in the design industry, they are usually created by human experts due to their extreme complexity, which is laborious and not practical for normal users. In recent years, some efforts have been made for automatic text effects transfer, however, the lack of data limits the capability of transfer models. To address this problem, we introduce a new text effects dataset, TE141K, with 141,081 text effects/glyph pairs in total. Our dataset consists of 152 professionally designed text effects, rendered on glyphs including English letters, Chinese characters, Arabic numerals, etc. To the best of our knowledge, this is the largest dataset for text effects transfer as far. Based on this dataset, we propose a baseline approach named Text Effects Transfer GAN (TET-GAN), which supports the transfer of all 152 styles in one model and can efficiently extend to new styles. Finally, we conduct a comprehensive comparison where 14 style transfer models are benchmarked. Experimental results demonstrate the superiority of TET-GAN both qualitatively and quantitatively, and indicate that our dataset is effective and challenging.
Dataset

Table 1. A summary of TE141K. Based on glyph types, TE141K can be split into three subsets, where styles are different in different subsets.
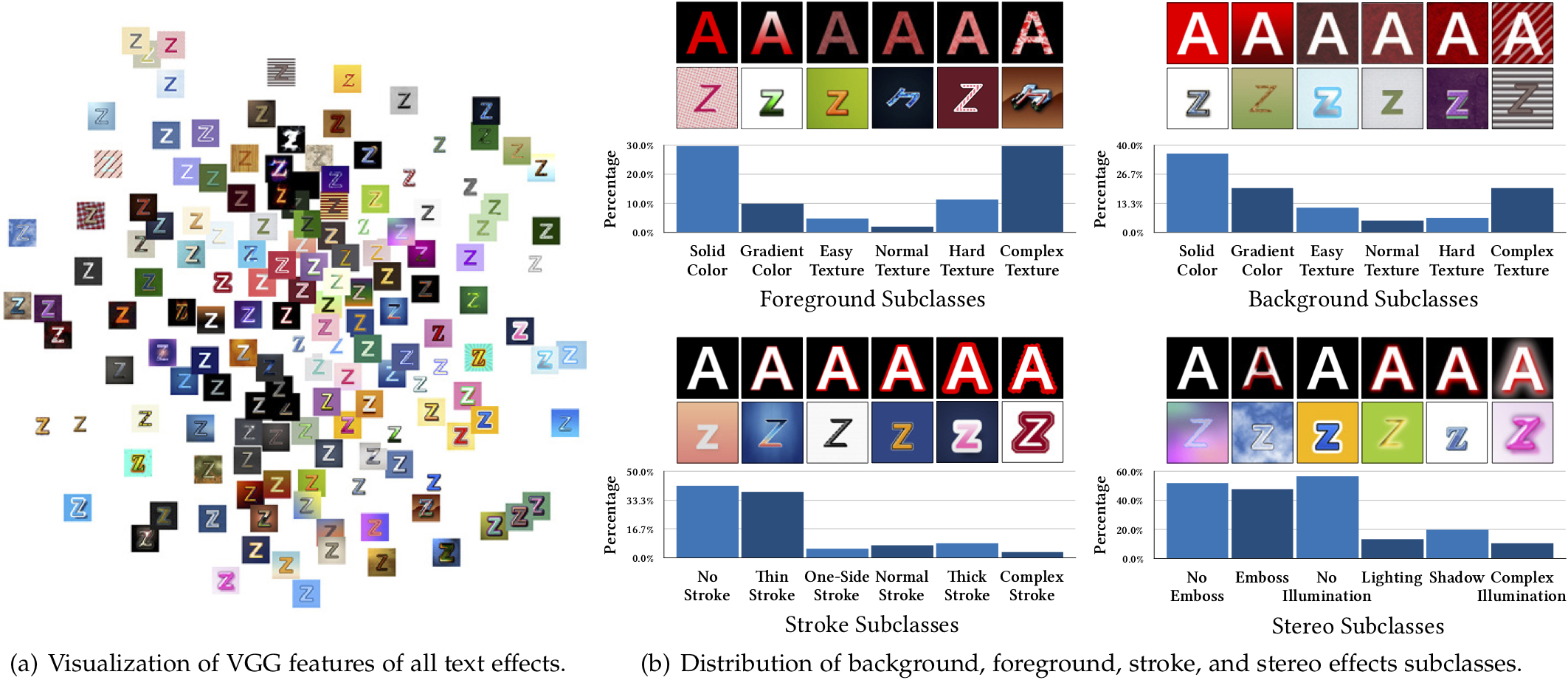
Figure 2. Statistics of TE141K. (a) Visualized text effects distribution in TE141K by t-SNE [1] based on their VGG [2] features. Perceptually similar text effects are placed closely to each other. The evenly dispersed distribution indicates the data diversity and richness of our dataset. (b) Distribution of different background, foreground, stroke, and stereo effects subclasses of our dataset. Representative images are shown at the top. The first row: schematics where red is used to represent specific text effects subclasses. The second row: representative samples from TE141K.
Resources
- Paper: arXiv
- Supplementary: Google Drive, Baidu Pan (Code: wvr6)
- Dataset: Google Drive, Baidu Pan (Code: knzy)
We also provide a list of links to the papers and corresponding codes of all benchmarked models, and a script for quantitative performance evaluation.
Citation
@article{
author = {Shuai Yang and Wenjing Wang and Jiaying Liu},
journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence},
title = {TE141K: Artistic Text Benchmark for Text Effect Transfer},
year = {2020},
}
Selected Benchmarking Results

Figure 3. Comparison with state-of-the-art methods on general text effects transfer. (a) Input example text effects with the target text in the lower-left corner. (b) AdaIN [3]. (c) WCT [4]. (d) Doodles [5]. (e) T-Effect [6]. (f) Pix2pix [7]. (g) BicycleGAN [8]. (h) StarGAN [9]. (i) TET-GAN.
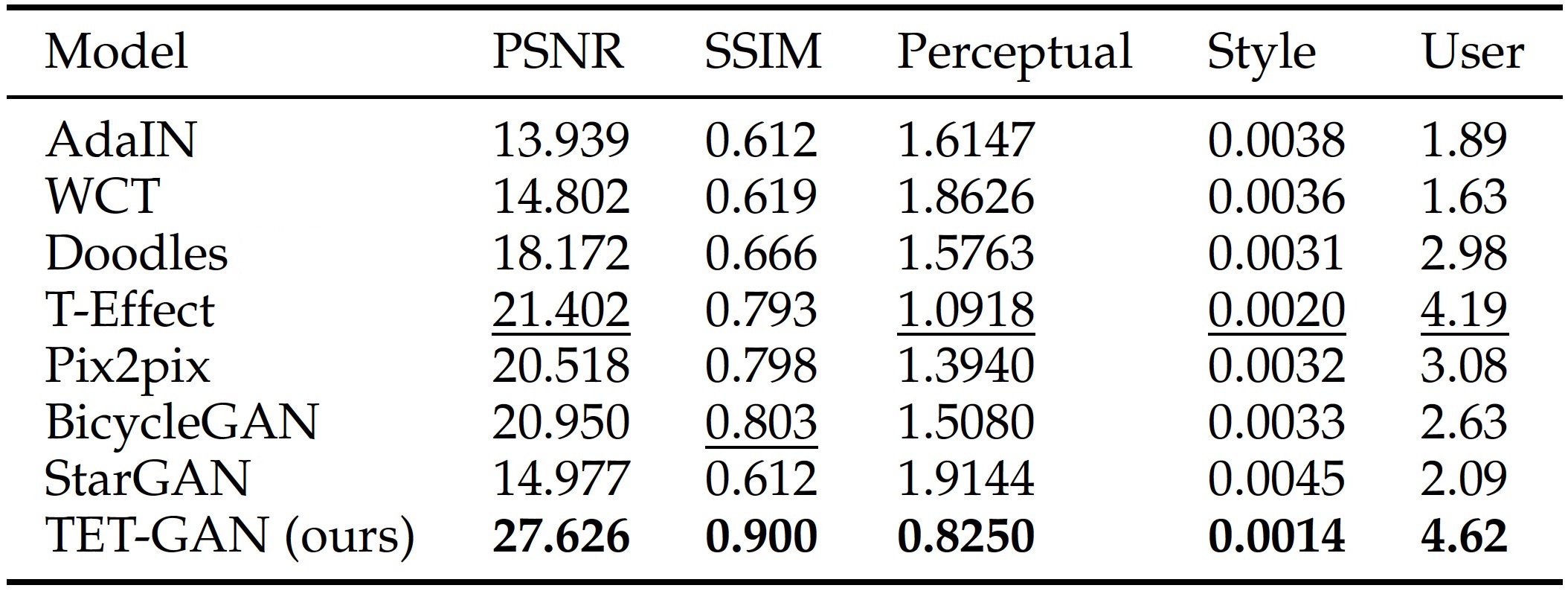
Table 2. Performance benchmarking on the task of general text effects transfer with PSNR, SSIM, Perceptual Loss, Style Loss, and the average score of user study. The best score in each column is marked in bold, and the second best score is underlined.
Reference
[1] L. v. d. Maaten and G. Hinton, “Visualizing data using t-sne,” Journal of machine learning research, vol. 9, no. Nov, pp. 2579–2605, 2008.
[2] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014.
[3] X. Huang and S. Belongie, “Arbitrary style transfer in real-time with adaptive instance normalization,” in Proc. Int’l Conf. Computer Vision, 2017, pp. 1510–1519.
[4] Y. Li, C. Fang, J. Yang, Z. Wang, X. Lu, and M.-H. Yang, “Universal style transfer via feature transforms,” in Advances in Neural Information Processing Systems, 2017, pp. 386–396.
[5] A. J. Champandard, “Semantic style transfer and turning two-bit doodles into fine artworks,” 2016, arXiv:1603.01768.
[6] S. Yang, J. Liu, Z. Lian, and Z. Guo, “Awesome typography: Statistics-based text effects transfer,” in Proc. IEEE Int’l Conf. Computer Vision and Pattern Recognition, 2017, pp. 7464–7473.
[7] P. Isola, J. Y. Zhu, T. Zhou, and A. A. Efros, “Image-to-image translation with conditional adversarial networks,” in Proc. IEEE Int’l Conf. Computer Vision and Pattern Recognition, 2017, pp. 5967– 5976.
[8] J.-Y. Zhu, R. Zhang, D. Pathak, T. Darrell, A. A. Efros, O. Wang, and E. Shechtman, “Toward multimodal image-to-image translation,” in Advances in Neural Information Processing Systems, 2017, pp. 465– 476.
[9] Y. Choi, M. Choi, M. Kim, J. W. Ha, S. Kim, and J. Choo, “Stargan: Unified generative adversarial networks for multi-domain image-to-image translation,” in Proc. IEEE Int’l Conf. Computer Vision and Pattern Recognition, 2018.